About the webserver
- Upload your files You should upload two separate files, one with the prototypical stressors and one with the events. Both files should be in a .txt or .TXT format, with a maximum of 10MB (please contact us if you have bigger files), and no special characters. For each file, please use one line by information (one event by line, or one stressor by line, even for the synonyms as they will be searched independently). You can also load an example prototypical stressor file and event file
- Output format option Please, choose the format for your results files. We propose 2 types of format : With abstracts and Without abstracts
- Refinement filter option The tool can refine the searches by combining a deletion of sentences containing context words with a lemmatization process. Lemmatization is a machine learning method for text normalization used in NLP that considers the context and converts the word to its meaningful base form. This option is very useful when terms from the event list have common stems (e.g. tests, testis -> test), and therefore the stemming process may lead to incorrect meanings and spelling errors.
- Reduced search option The tool can perform the searches in the full abstracts or without considering the beginning part, which appears to be covered usually by the first 20% of the abstracts. This option allows to avoid too many false positive, as the introduction part often reflect a working hypothesis.
For more details of the refinement option, please read the method section below and the supplementary material.
For more details of the refinement option, please read the method section below and the supplementary material
AOP-helpFinder is provided without any warranty. But if you have any problemes please feel free to contact us by mail.

- Upload your files You should upload a file containing the list of events you wish to link. The file should be in a .txt or .TXT format, with a maximum of 10MB (please contact us if you have bigger files), and no special characters. Please use one line by information (one event per line, even for synonyms as they will be searched independently). You can also load an example event file
- Output format option Please, choose the format for your results files. We propose 2 types of format : With abstracts and Without abstracts
For more details of the refinement option, please read the method section below and the supplementary material
AOP-helpFinder is provided without any warranty. But if you have any problemes please feel free to contact us by mail.

This module run the both analysis. First it run the stressor-event module and in a second time it run the event-event module with the same event lists. Please see 3a and 3b for more information.

You can download your result files as a .zip archive. Please note that it will be automatically deleted after one month.
Automated report : we add a automated report with different informations as the parameters used, figures and basic informations example zip for prototypical stressor - event
example zip for event - event
For both prototypical-stressor / event and event /event search, please note that .xlsx files are dynamic : click on the PMID to be forwarded to the corresponding PubMed page. This option is only available if the number of links is strictly lower than : 65 530.
About the method
Kans J. Entrez Direct: E-utilities on the Unix Command Line. 2013 Apr 23 [Updated 2021 Apr 29]. In: Entrez Programming Utilities Help [Internet]. Bethesda (MD): National Center for Biotechnology Information (US); 2010-. available from: https://www.ncbi.nlm.nih.gov/books/NBK179288/
Achakulvisut et al., (2020). Pubmed Parser: A Python Parser for PubMed Open-Access XML Subset and MEDLINE XML Dataset XML Dataset.Journal of Open Source Software, 5(46), 1979, https://doi.org/10.21105/joss.01979
- Pre-processing A pre-processing multi-steps procedure will allow to prepare all extracted abstracts from the PubMed database. First the abstracts are cleaned : abstracts are split in sentences, we remove the negative sentences then the stop words (a, and, the ...). Finally, a stemming process is performed on each word.
- Score method using the position of the event A score is calculated for each pre-processed abstract using the position of the identified event in the text. This was developed as stressor-event are usually co-mentioned at the beginning of the abstract to refer to a working hypothesis, whereas when they are co-mentioned at the end it is more likely to be related to results and findings ("reduced search" option)
- Score method using graph theory For each pre-processed abstract the algorithm will look for the events sequentially (using the use list of events). If the tool finds at least 3/4 of the words from one event, it computes a distance score based on Dijkstra algorithm. In this version the grammatical context is taken into account with lemmatization and work context ( see ‘refinement filter’ option).
A new module called "refinement option" has been developed to facilitate further analysis of the results, that can be for ex. by manual curation. This refinement option will only applied on the selected abstracts from the pre-processing run. As in the pre-processing step, the refinement option will split the abstracts into sentences, remove the negative sentences and the stop words. But instead of stemming the words, the option will use the lemmatization process that considers the context and converts the word to its meaningful base form. Then, AOP-helpFinder tool will removes the sentences containing "context word" (ex: suggest,... ).Then the scores as described in "3.Pre-processing and scoring" will be computed. This step is proposed as an option only for prototypical stressor -event search as it is more time consuming.
To facilitate interpretation, the results of these tests are classified into 5 categories according to the strength of the link: “Low”; "Quite low"; "Moderate"; "High" ; "Very high". A Cs = Low means that a stressor-event or event-event link is not very well studied or defined, while a Cs = Very high means that the link has been very well studied. Nevertheless, a Low Cs does not mean that a link does not exist, but warns the user to manually check the result by reading the articles provided by AOP-helpFinder. For very general events (studied in a wide range of fields), you may get a Cs=Low even if the link is well defined.
/!\ Low Cs does not mean that a link does not exist, but warns you to check the link in the literature extracted by AOP-helpFinder.
For more details, please see the article:
doi: 10.1016/j.envint.2023.108017.
prototypical stressor - event search:
- distribution_events.pdf
- distribution_stressors.pdf
- distribution_years.pdf
- distribution_scores.pdf
- heatmap(s)
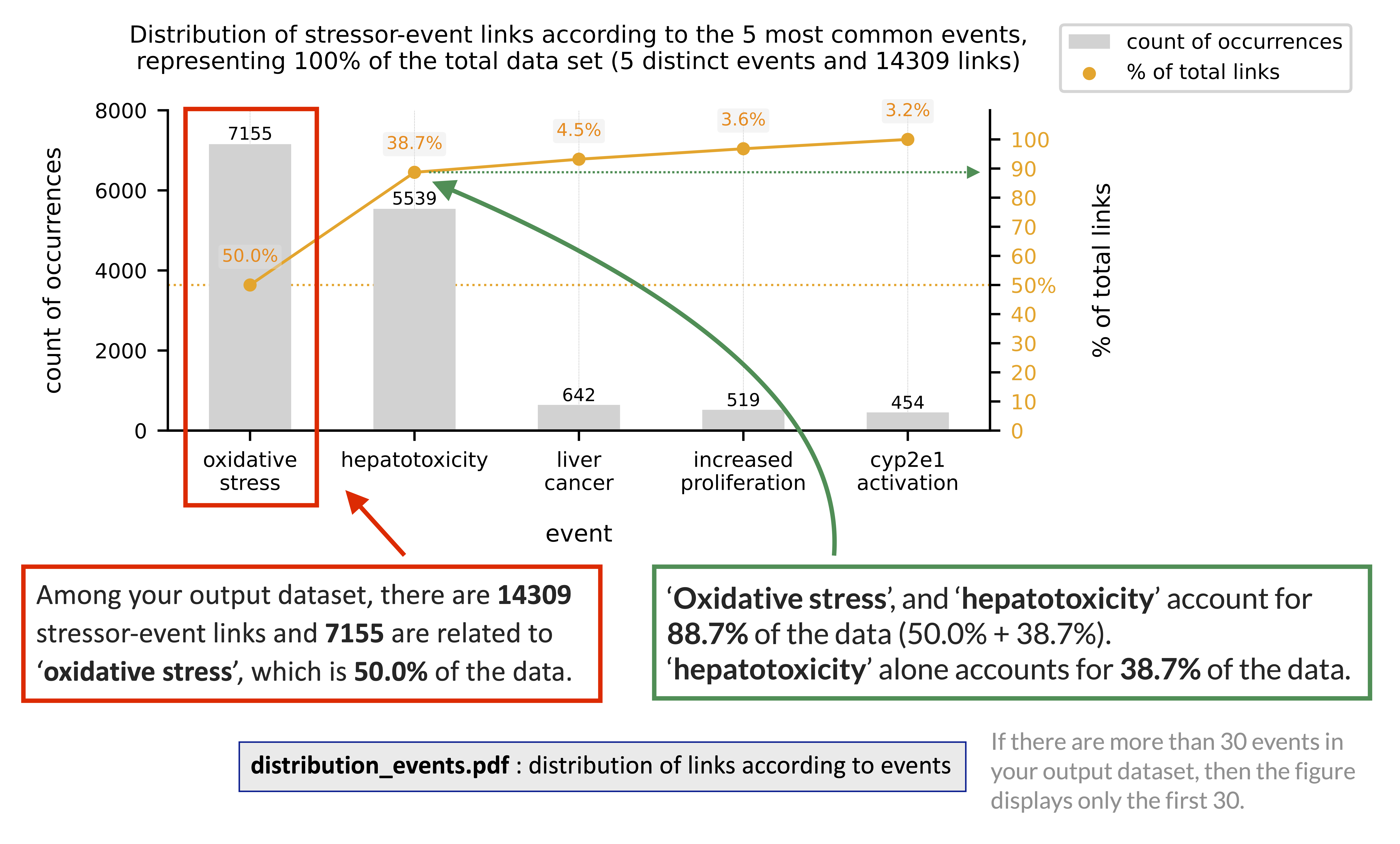
distribution of links according to events
distribution of links according to stressors
distribution of articles according to their publication date
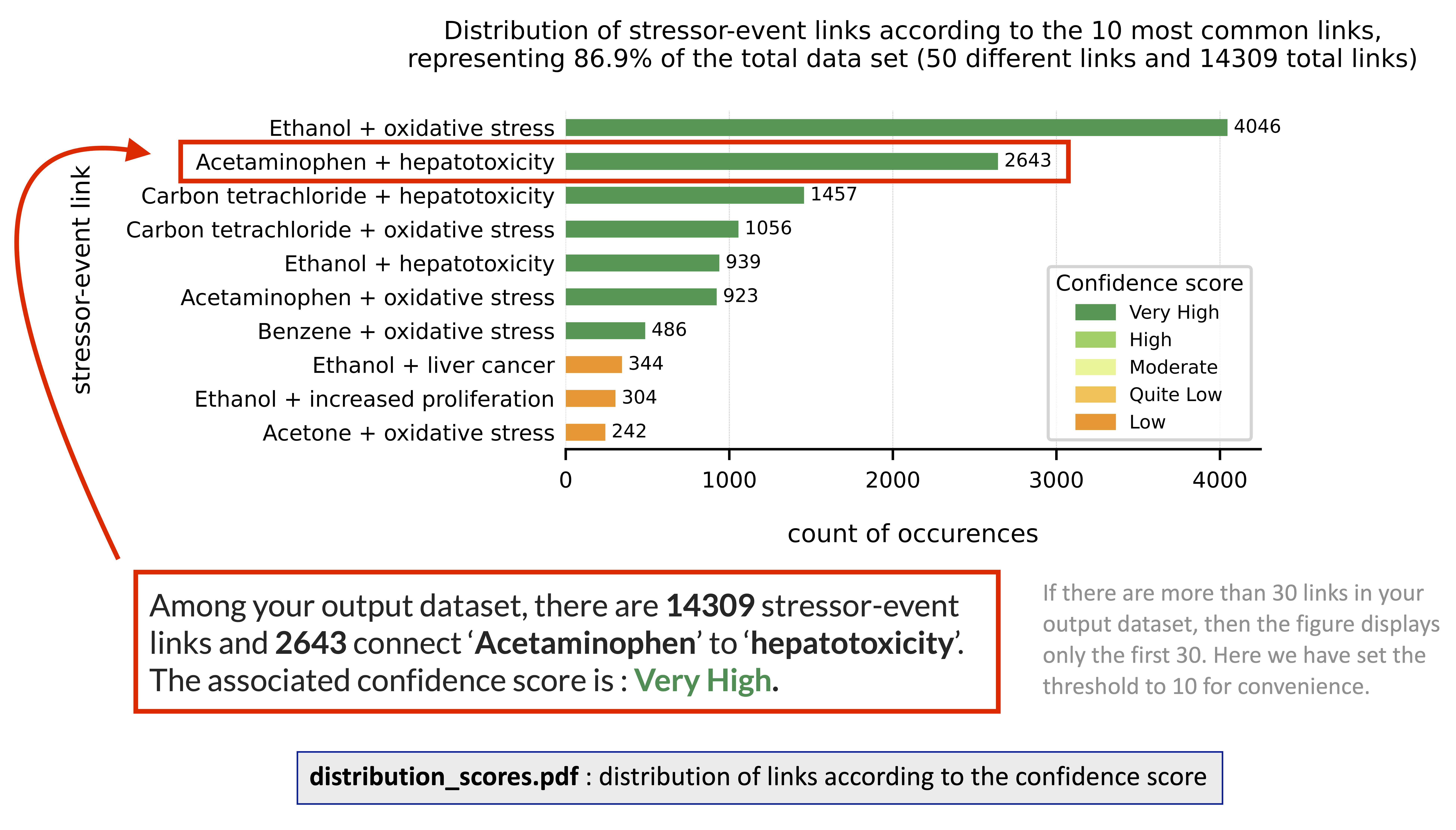
distribution of links according to the number of papers and confidence score
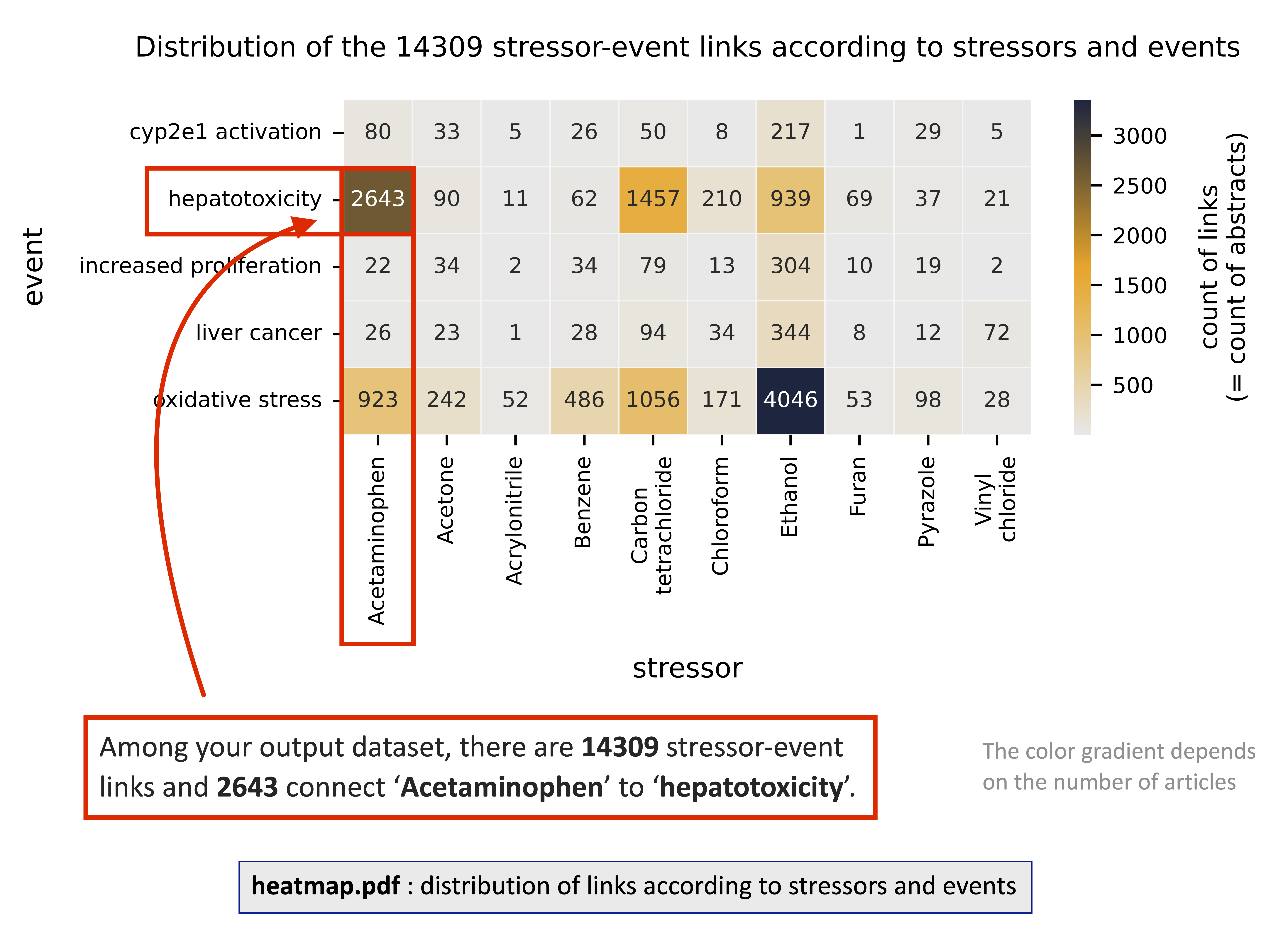
distribution of links according to stressors and events (two versions : one where the color scale depends on the number of papers and the other one where it depends on the confidence score)
event - event search:
- distribution_years.pdf
- distribution_scores.pdf
distribution of articles according to their publication date
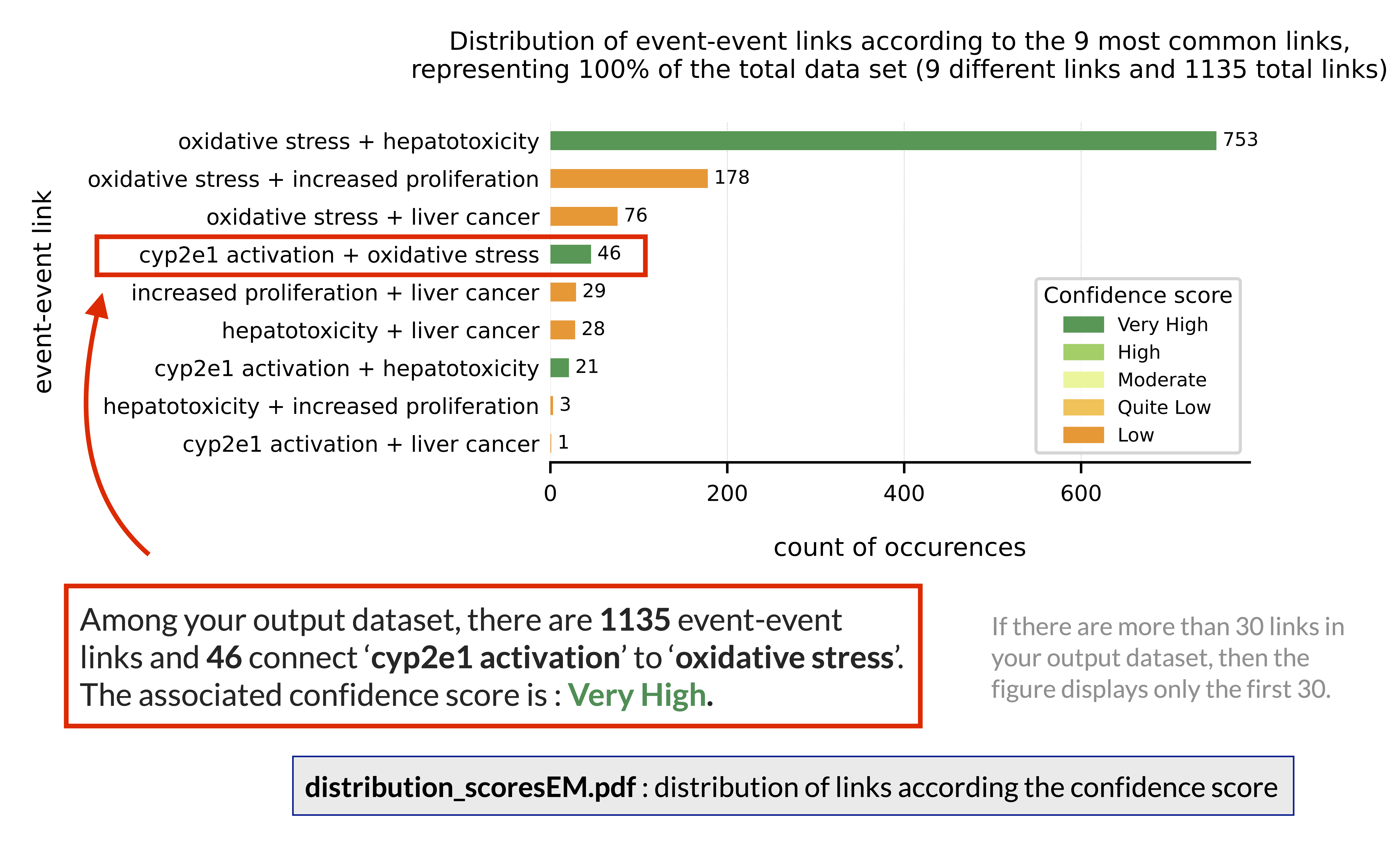
distribution of links according to the number of papers and confidence score
For both prototypical-stressor / event and event /event search, please note that .xlsx files are dynamic : click on the PMID to be forwarded to the corresponding PubMed page. This option is only available if the number of links is strictly lower than : 65 530.
for more information please see the article:
doi: 10.1093/bioinformatics/btaf381